本文不代表我的雇主。
一、
很多人都注意到,AlphaGo 的棋风有个有意思的特点:它很少下出「好棋」,也就是凶狠的杀招,并且还时不时似乎下出缓手。它局面从未大幅领先过,永远只赢一点点。
为什么呢?
要训练一个神经网络,需要定义一个反馈函数,即告诉这个神经网络怎样的决策是好的。在 AlphaGo 的设计中有个重要的细节:训练 AlphaGo 的神经网络时所采用的反馈函数只依赖于输赢,而同输赢的幅度无关。换言之,对 AlphaGo 而言,赢一目的棋和赢十目的棋一样好,它追求的只是单纯的胜负而已。
但单纯追求胜率实际上就意味着放弃追求大胜。因为在多元优化问题中靠近边缘的地方,不同的优化目标之间几乎总是彼此矛盾的。比方说,如果一个局面需要考虑三手可能的棋,第一手可以赢十目,有 70% 的胜率,第二手可以赢一目,有 80% 的胜率。第三手可以赢二目,有 90% 的胜率。首先第二手棋显然全面劣于第三手棋,不应该列入考虑。而值得比较的第一和第三手棋之间,胜率高的选择一定是胜利幅度较低的那一个。——很显然,这就是典型的帕雷托优化问题。第二手棋不是帕雷托最优的,或者说不够接近优化的边缘。而在边缘处的第一手和第三手,两个指标的优劣一定彼此相反。
(这当然不是说,围棋中追求胜率和追求领先幅度是两件矛盾的事。事实上,在绝大多数情况下,它们的指向都是相同的,一手导致领先幅度大幅下降的棋一般来说也会导致胜率大幅下降,但它根本就不会被列入权衡,也就不会被注意到。值得权衡的选择之间一定是彼此两难的,并且对手愈强,这两个优化目标之间的分歧就越大。)
因此,AlphaGo 以单纯胜负作为反馈函数的结果,就是 AlphaGo 总是选择那些相对而言更保证胜率而胜出幅度较小的棋。只赢一点点就够了。
为什么人类棋手(至少绝大多数)不这么下棋呢?
因为这和人的思维方式不符。AlphaGo 可以这么做的前提是极端精细的计算能力,从而得以控制微小而稳定的盘面优势。像是贴着水面飞行的鸟,最危险但也最省力。但人无法永远做出精确的计算,所以需要一次次努力扩大领先的幅度以维持一个安全的距离,防止一着不慎胜负翻盘。所以 AlphaGo 会显得遇强则强,但也很少下出「好看」的棋。甚至可能因为过于追求全局取胜几率,下出在人类的视角看来局部并非最优的招式。反过来,通过一番搏杀来取得局部胜利在人类看来总是一件好事,而在 AlphaGo 看来,这也许只是毫无必要地增加不确定性而已。
于是我忍不住设想,如果 AlphaGo 在训练时采用不同的反馈函数会是什么结果。不妨假设存在一个 BetaGo,一切都和 AlphaGo 设定相同,只是反馈函数定义为盘面领先的目数。(换言之,从一个正负之间的阶梯函数变成线性函数。)可以猜测 BetaGo 的「棋风」应该比 AlphaGo 凶狠许多,更追求杀着,更希望大赢。如果让 BetaGo 和 AlphaGo 反复对战,AlphaGo 赢的次数会更多,但平均而言 BetaGo 赢的幅度会更大。
(或者更极端一点,干脆采用盘面领先程度的平方乃至指数函数作为反馈,那会培养出什么暴躁疯狂的算法呢?)
AlphaGo 采用目前的设计是很好理解的,因为首先追求的目标还是证明 AI 能够战胜人脑。但是从目前的情况来看,AlphaGo 似乎已经遥遥领先,那即使 BetaGo 胜率稍差,假以时日应该也可以超过人类。而它的棋应该会好看很多。
好可惜和李世乭对战的不是 BetaGo 啊⋯⋯
二、
AlphaGo 是否会打劫终于不成为争议了。
但它其实根本就不是一件应当被争议的事。打劫只是围棋中「不得全局同形再现」这一条规则的推论,而这条规则对 AI 来说实现起来再简单不过:只要在搜索决策树的时候,跳过所有已经出现过的局面就好了。
这当然不是说,AlphaGo 的实现细节中一定没有任何针对劫的专门逻辑存在。一些特定的优化也许是有意义的。但是以为 AlphaGo 和人一样,有必要去辨认劫的特性,选择和保存劫材,在多个劫同时存在的局面下做复杂的战略决策,只不过是把人的思维方式错误地套用在遵循完全不同逻辑的神经网络上而已。神经网络自我学习的特性保证了只要让它遵循围棋的基本规则,它完全可以「显得」像是懂得复杂的围棋概念,但这绝不意味着它真的「在乎」这些概念。AlphaGo 的主要作者中的两位 Chris Maddison 和 Aja Huang 在他们 2015 年发表过的一篇论文 Move Evaluation in Go Using Deep Convolutional Neural Networks 中写过这样一段话(原文为英文,以下是我的翻译):
很明显,神经网络内在地理解了围棋的许多深奥的层面,包括好形,布局,定式,手筋,劫争,实地,虚空。令人惊异的是这样一个单独、统一、直接的架构就能把围棋的元素掌握到这个程度,而不需要任何明确的先导。
归根结底,劫是一个完全人为构造的概念。人们用它来描述自己的战略,建构自己的思考模式,就像别的围棋术语一样。但它只是刻画,并非本质。如果 AlphaGo 有意识,它也许会在面对人类的询问时说:噢,原来你把我走的这一步叫做打劫啊。
但这是人类的缺陷么?我们是否是在把一个本来应该用纯粹的计算解决的问题毫无必要地归纳于概念,然后又让自己的思维囿于这些概念而作茧自缚呢?
恰恰相反。能够迅速建立起高级抽象的概念,然后用它来简化和指引决策,这是人类在千百万年间进化出的伟大能力,今天的人工智能还远远不能望其项背。借助这些抽象观念,人们得以把全局问题分解为一系列局部的可以简明描述和推理的子问题,做出也许未必在数值上严格最优但是相当接近最优的判断,从而取代人工智能需要耗费海量计算才能作出的决策。更重要的是,这些抽象观念可以让一个人从极少数样本中辨认本质,总结经验,汲取教训,获得成长。一个棋手从观摩一盘棋中得到的教益,可以多于 AlphaGo 千万盘自我对局。AlphaGo 的神经网络自我反馈训练虽然有效,但是盲目。而人们知道自己要学的是什么。
这是人类智能最耀眼的优势之一。
这引出了下面进一步的问题:这两种思维方式是否有可能对接?能不能让 AlphaGo 把自己的决策过程翻译为人类可以理解的概念和语言呢?
这件事在应用上的潜力显而易见(用人工智能来辅助教学,当然不限于围棋),但更重要的是它在理论上的挑战。AlphaGo 的决策过程是个黑箱,我们能够提炼出它用来提取棋局特征的元素,但无法直接理解它们意味着什么。我们不知道它们如何对应于人所熟悉的概念,或者在那里是否存在人们尚未总结出的新知识。我们当然可以看到它最终的结论,例如一步棋是好是坏,可是仅有结论并没有太多用处。
但这里仍然有做文章的余地。AlphaGo 可以看做是一个记录了自己每一次神经脉冲细节的人工大脑,而机器学习的原理也可以应用在这些海量的记录数据本身之上。不难设想,也许可以训练出另一个神经网络来识别出这些数据中对应于人类高级概念的特征,从而设法把 AlphaGo 的决策过程拆解和翻译为人类熟悉的观念模块。如果可以实现这一点,人类就可以更直观地理解 AlphaGo。
我不知道这能否实现,但我希望可以。那将是一个重大的飞跃。
到那时,我们也许就可以看到人类棋手和 AlphaGo 在真正的意义上「复盘」了。
三、
我们离围棋之神还有多远?
关于 AlphaGo 最大的未知数之一,是它自我对局训练的效率。按照目前公开的讯息,它的棋力一直在随着时间稳定上升,直到不久之前刚刚超越了人类顶尖棋手的水准。看起来假以时日,它的棋力还会进一步成长。
但这个预计完全在未定之天。事实上,过去这段时间以来它的棋力增长本身是个奇迹,而非必然。通过自我对局的输赢反馈来提升能力,最大的问题在于容易陷入机器学习中所谓「过拟合」的状态。简单地说,就是因为自己的对手也是自己,从而陷入一个自洽的逻辑圈无法自拔。其结果是缺陷变成了优势,盲点变成了禁区。初始经验中的噪音,逐渐固化成了金科玉律。实际上并不存在的界限,因为从来没有试图跨越,结果变成了真的限制。最后「自以为」自己下得很好,而且越下越好,其实只是越来越适应自己而已。
DeepMind 的团队当然想到了这个问题。他们的解决方案是不仅仅让 AlphaGo 自我对弈,也不断让不同等级的 AlphaGo 之间互相越级对弈作为校准,以避免出现随着不断进化,客观棋力反而萎缩的现象。问题在于,这种校准终究是在 AlphaGo 的「家族」内部进行的,因为这世界上暂时还不存在可以和它媲美的第二家对弈系统,可以进行大规模的互相检验。自己近亲繁殖的结果是有些 bug 永远都无法被自己意识到,只有在和棋风棋路截然不同的对手的对弈中才有可能暴露出来。
譬如人类这个对手。AlphaGo 和李世乭的对弈,可以看做是它第一次遇到和自己旗鼓相当而截然不同的异类。于是它果然崩溃了一次。
其实和人类棋手相比,AlphaGo 也并非完全是天外来客。它最初的训练来自大量人类棋手的网络围棋对局,血液里保存着人类棋手的基因。正因为如此,DeepMind 公司已经宣布,将在接下来的几个月里重新来过,在不依赖人类对局数据的基础上,从零开始训练新的围棋程序,以探索不落现有围棋观念窠臼的新道路。
但即便如此,它仍然无法避免有一天终究会落入过拟合的陷阱。要逐渐接近围棋之神的境界,可能需要不止一个竞争者出现,彼此切磋训练才有可能做到。甚至可以想象,人们最终会找到随机生成新的围棋算法的方法,海量生成大量竞争者。但要做到这一点,需要人们对围棋和人工智能有远比今日更深刻的理解才行。
长远来看,探索围棋的规律,和探索围棋算法的规律,在宏观的时间尺度下本来不就是一回事么?
从某种意义上说,在遇到 AlphaGo 之前的人类围棋,整体上也是一个自我繁殖而逐步陷入过拟合的家族。虽然江山代有才人出,但是作为一个集体,始终在继承着相似的传统,遵循着统一的范式。现成的定式和规律已经被研究地如此透彻,以至于任何新颖的想法都会因为初生时的弱小而昙花一现。在千年围棋史上,也许只有本因坊道策和吴清源曾经以一人之力掀起过整个围棋观念的革命。绝大多数情况下,后来者只是在通过自己的努力进一步强化既有的棋理而已。
直到 AlphaGo 的出现。
于是我们看到一个强大的传统遇到了新奇而健壮的挑战者。从一开始不屑的讪笑,变成了敬畏的崇拜,直到最终勇敢的接纳。这并非一朝一夕之功,当然总是会有抗拒和怀疑,会有恐惧、愤怒和绝望。更坎坷的部分也许还在后面。但是这一步一旦走出,就无法再后退了。
归根结底,这是避免一个自我封闭的系统陷入衰败的唯一途径。固步自封,夜郎自大,筑起墙来抵御想象中的危险,把自我适应的沉渣视为不可动摇的根本,绝无可能生生不息欣欣向荣,而只会在自我满足的道路上越走越远。
当然不止下棋是这样。
四、
有趣的是,人类对人工智能发展速度的预期,常常既极端低估,又极端高估。在 AlphaGo 挑战李世乭之前,大多数人本能地拒绝相信人工智能可以达到这样的高度,认为围棋中某些普遍被认为是属于人类的强项,例如大局观、直觉、平衡感、洞察力,是人工智能不可逾越的高峰。甚至有些人在看到对局结果之后,还是固执坚信人工智能只是以暴力和统计学堆叠出胜利,并没有真正展现出人类大脑特有的能力。但另一方面,很多人又在一夜之间开始担忧人工智能统治人类的未来,似乎人工智能从学会下围棋到征服世界,只有一步之遥。
而事实是,人工智能早就开始在许多关于直觉和美的领域里展现出创造性。三十年前,Harold Cohen 已经开始能够让电脑自动画出人们误以为来自人类画家的画作。二十年前,David Cope 编写的程序写出的肖邦风格的马祖卡舞曲已经传神到即使音乐专业的听众也难辨真伪。归根结底,人的大脑在功能性的层面上只是一架精密的机器而已。既然是机器,就有被数值计算模拟和逼近的可能性。AlphaGo 所展现出的围棋开局时良好的「棋感」,再好不过地说明了所谓的直觉并非无法量化,只是无法被我们自己量化而已。
但这是人类的失败么?
从茹毛饮血的穴居时代到游弋太阳系的今天,人类的进步从来就不体现为本身生物能力的优越,而体现于不断创造出工具成为自我的延伸。我们制作出的机器跑得更快,飞得更高,算得更准,想得更深。但是归根结底,定义人性的并不是我们的能力,而是我们的弱点,以及我们为了克服自身缺陷和拓展未知的边界所作出的艰苦卓绝的努力。在这个过程中,在一次又一次失败里,我们砥砺心灵、认识自我、战胜蒙昧和愚蠢,然后成长。
我曾经和朋友谈及有哪些人工智能还做不到的事情。朋友说:人工智能至少无法设计出 LIGO 这样的科研工程来探测引力波。我说:我不相信。LIGO 当然是人类智慧的结晶,但是考虑到人类所能掌握的资源的有限可能性,让人工智能设计出整套方案并非不可能。
我真正觉得人工智能无法做到的,是「想要探测引力波」这件事。
所以机器的发明从不曾阻止我们在健身房里挥汗如雨,或者寻求素数定理的一个又一个新的证明。印刷术没有取代书法,数字音乐的普及也无法消灭演唱会现场的泪水和欢呼。在围棋三尺天地的手谈之中,在须臾之间寸争胜败的纤毫境界里,人们所付出的长久凝视和坚忍血汗,所寻找到的对世界和彼此的理解,绝不会因为 AlphaGo 的出现而烟消云散。
它是我们的进步的一部分。
纹枰对坐,从容谈兵。
研究棋艺,推陈出新。
棋虽小道,品德最尊。
中国绝技,源远根深。
继承发扬,专赖后昆。
敬待能者,夺取冠军。
——陈毅《题<围棋名谱精选>》
是为结束。
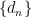 为第
为第 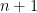 个素数和第
个素数和第  个素数之差。数列
个素数之差。数列  在
在  ,则上述两则猜想可以分别表述为
,则上述两则猜想可以分别表述为  。
。 ,下降了一百倍还多。
,下降了一百倍还多。 使得每
使得每 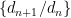 的下界趋于
的下界趋于  ,上界趋于
,上界趋于  。同样是在张益唐的结论和他所用的工具的基础上,Pintz 证明了这个猜想不但是对的,而且很强:
。同样是在张益唐的结论和他所用的工具的基础上,Pintz 证明了这个猜想不但是对的,而且很强: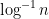 ,上界趋于
,上界趋于 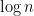 。
。