2016 年 1 月 28 日,Deepmind 公司在 Nature 杂志发表论文 Mastering the game of Go with deep neural networks and tree search,介绍了 AlphaGo 程序的细节。本文是对这篇论文的阅读笔记,以及关于人工智能和围棋进一步的一些想法。
声明:我是数学 PhD 和软件工程师,但不是人工智能领域的专家。我也不会下围棋。
一、
AlphaGo 总体上由两个神经网络构成,以下我把它们简单称为「两个大脑」,这并非原文中的提法,只是我的一个比喻。
第一个大脑(Policy Network)的作用是在当前局面下判断下一步可以在哪里走子。它有两种学习模式:
一个是简单模式,它通过观察 KGS(一个围棋对弈服务器)上的对局数据来训练。粗略地说:这可以理解为让大脑学习「定式」,也就是在一个给定的局面下人类一般会怎么走,这种学习不涉及对优劣的判断。
另一个是自我强化学习模式,它通过自己和自己的海量对局的最终胜负来学习评价每一步走子的优劣。因为是自我对局,数据量可以无限增长。
第二个大脑(Value Network)的作用是学习评估整体盘面的优劣。它也是通过海量自我对局来训练的(因为采用人类对局会因为数据太少而失败)。
在对弈时,这两个大脑是这样协同工作的:
第一个大脑的简单模式会判断出在当前局面下有哪些走法值得考虑。
第一个大脑的复杂模式通过蒙特卡洛树来展开各种走法,即所谓的「算棋」,以判断每种走法的优劣。在这个计算过程中,第二个大脑会协助第一个大脑通过判断局面来砍掉大量不值得深入考虑的分岔树,从而大大提高计算效率。
与此同时,第二个大脑本身通过下一步棋导致的新局面的优劣本身也能给出关于下一步棋的建议。
最终,两个大脑的建议被平均加权,做出最终的决定。
在论文中一个有趣的结论是:两个大脑取平均的结果比依赖两者各自得出的结果都要好很多。这应当是让 AlphaGo 表现出和人类相似性的关键所在。
二、
如果我是这篇论文的审稿人,我会对论文提出下面这些问题和评论:
首先,这些神经网络训练在很大程度上是通过自我对局来实现的。这既是某种优势(按照 Facebook 人工智能研究员田渊栋的说法,几千万自我对局这种规模是相当惊人的数据量),某种程度上来说也是不得已而为之,因为人类对局的总数实在太少,会导致机器学习中常见的过度拟合问题。
但是这样是否有可能造成自我设限乃至画地为牢的后果?这同时牵涉到人们对神经网络学习过程的理解和对围棋本身的理解。一方面,神经网络本身是否包容一定程度的「think out of the box」的能力,这固然取决于具体的神经网络算法,但也确实是人们对神经网络方法的一个本质困惑。另一方面,因为 AlphaGo 最基础的定式仍然是来源于人类对局,因此,这个问题依赖于人类棋手本身是否已经穷尽了围棋中所有有意义的基本定式。
(作为一个案例,在 AlphaGo 和樊麾的第二盘对局中,很多人都注意到 AlphaGo 走了一个不标准的大雪崩定式,这是说明 AI 学错了呢,还是它发现这是更好的走法?)
其次,这两个大脑的工作方式确实和人类很相似,一个判断细部,一个纵览全局。但 AlphaGo 最终的结合两者的方式相当简单粗暴:让两者各自评估一下每种可能的优劣,然后取一个平均数。这可绝不是人类的思维方式。
对人类来说,这两种思考问题的方式的结合要复杂的多(不仅仅是在围棋中是这样)。人们并不是总是同时对事态做出宏观和微观的判断,而是有时候侧重于大局,有时候侧重于细部。具体的精力分配取决于事态本身,也取决于人在当时的情绪、心理和潜意识应激反应。这当然是人类不完美之处,但也是人类行为丰富性的源泉。
而 AlphaGo 固然体现出一定的大局观,但从具体算法看来,它在为了宏观优势做出局部牺牲这方面的能力和人类完全不能相提并论。AlphaGo 引入整体盘面评估确实是它胜于许多别的围棋 AI 的地方,但从根本上来说,这只是人们让 AI 具有「战略思维」的尝试的第一步,还有太多可以改进的可能性。
最后,和很多别的围棋 AI 一样,当 AlphaGo 学习盘面判断的时候,采用的是图像处理的技术,也就是把围棋棋盘当做一张照片来对待。这当然在技术上是很自然的选择,但是围棋棋局究竟不是一般意义上的图案,它是否具有某些特质是常见的图像处理方法本身并不擅长处理的呢?
三、
为什么要让人工智能去下围棋?有很多理由。但在我看来最重要的一个,是能够让我们更深入地理解智能这件事的本质。
神经网络和机器学习在过去十年里跃进式的发展,确实让 AI 做到了许多之前只有人脑才能做到的事。但这并不意味着 AI 的思维方式接近了人类。而且吊诡的是,AI 在计算能力上的巨大进步,反而掩盖了它在学习人类思维方式上的短板。
以 AlphaGo 为例。和国际象棋中的深蓝系统相比,AlphaGo 已经和人类接近了许多。深蓝仍然依赖于人类外部定义的价值函数,所以本质上只是个高效计算器,但 AlphaGo 的价值判断是自我习得的,这就有了人的影子。然而如前所述,AlphaGo 的进步依赖于海量的自我对局数目,这当然是它的长处,但也恰好说明它并未真正掌握人类的学习能力。一个人类棋手一生至多下几千局棋,就能掌握 AlphaGo 在几百万局棋中所训练出的判断力,这足以说明,人类学习过程中还有某种本质是暂时还无法用当前的神经网络程序来刻画的。
(顺便提一句,很多评论认为 AlphaGo 能够通过观察一个特定棋手的对局来了解他的棋风以做出相应的对策。至少从论文来看,这几乎确定是不可能的事。一个棋手的对局数对 AlphaGo 来说实在太少,无从对神经网络构成有效的训练。观察和总结一个人的「棋风」这件事仍然是人类具有完全优势的能力,对电脑来说,这恐怕比赢棋本身还更难一些。)
这当然不是说,AlphaGo 应该试图去复刻一个人类棋手的大脑。但是 AlphaGo 的意义当然也不应该仅仅反映在它最终的棋力上。它是如何成长的?成长曲线具有什么规律?它的不同参数设置如何影响它的综合能力?这些不同参数是否就对应了不同的棋风和性格?如果有另一个不同但水平相当的 AI 和它反复对弈,它能否从对方身上「学到」和自我对弈不同的能力?对这些问题的研究和回答,恐怕比单纯观察它是否有朝一日能够超越人类要告诉我们多得多的知识。
因此,即使 AlphaGo 在三月份战胜了李世乭,在我看来也是另一扇大门的开启而非关闭。事实上,即使就围棋发展本身而论,如果把 AlphaGo 的两个大脑以如此简单的方式线性耦合起来就能胜过人类,那只能说明人们对围棋的规律还有太多值得探索的空间。
而对人工智能领域来说,AlphaGo 和一切神经网络一样,本质上还只是个大黑盒,我们能观察到它表现出的巨大能力,但对它究竟是如何「思考」的这件事依然所知甚少。在工程上,这是个伟大的胜利。在科学上,这只是万里长征的第一步而已。
AlphaGo 项目主页:http://www.deepmind.com/alpha-go.html
Nature 论文:http://www.nature.com/nature/journal/v529/n7587/full/nature16961.html
Nature 报道:http://www.nature.com/news/google-ai-algorithm-masters-ancient-game-of-go-1.19234
Dan Maas 对论文的浅显总结:http://www.dcine.com/2016/01/28/alphago/

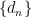 为第
为第 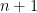 个素数和第
个素数和第  个素数之差。数列
个素数之差。数列  在
在  ,则上述两则猜想可以分别表述为
,则上述两则猜想可以分别表述为  。
。 ,下降了一百倍还多。
,下降了一百倍还多。 使得每
使得每 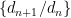 的下界趋于
的下界趋于  ,上界趋于
,上界趋于  。同样是在张益唐的结论和他所用的工具的基础上,Pintz 证明了这个猜想不但是对的,而且很强:
。同样是在张益唐的结论和他所用的工具的基础上,Pintz 证明了这个猜想不但是对的,而且很强: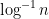 ,上界趋于
,上界趋于 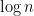 。
。